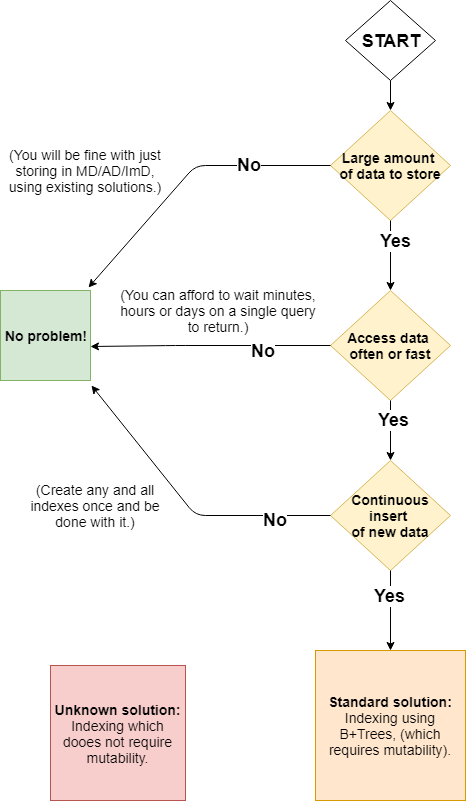
Background
Simple, fast and efficient data storage and retrieval is one of my favorite subjects within SAFENetwork scope. As you might know I have been doing some implementations to try and see how the current API can be used for it.
There’s currently a proposal being made for replacing MutableData with AppendableData. The discussion can be followed here: Appendable Data discussion - #282 by Anonymous2020
My previous implementation based on MD will have to adapt, and for that I have come up with the following, which is still a work in progress.
When I was asked to provide some requirements for the DataStore, I thought I’d go through what my thinking is so far with regards to AD in the context of SAFE.DataStore, and present them in it’s own post. I have mostly thought of this in terms of what can be done, with what we have, i.e. it’s been very investigative, and continues to be, and for that reason I haven’t really set out a goal for what should be accomplished.
Anyway, here goes.
EDIT:
As per request of @Southside (thanks for bringing my attention to it!) I’ll include a chart to explain the Big O notation used further down:
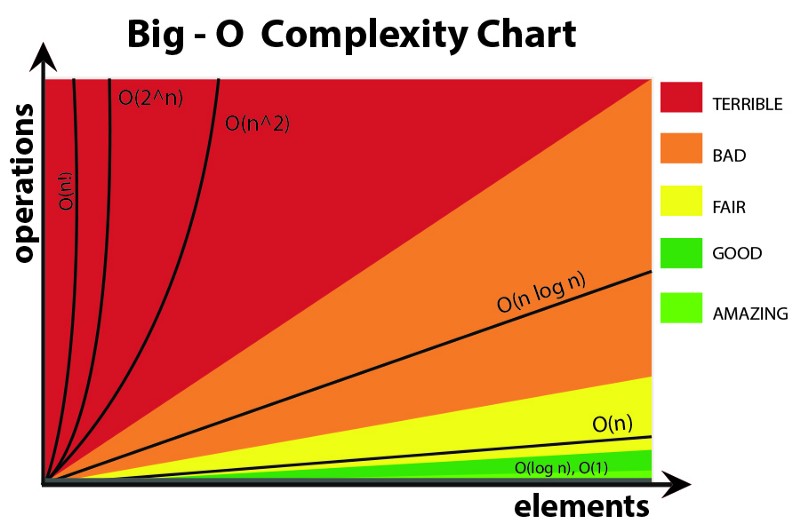
(Thanks @draw for looking up the chart.)
Requirements for AppendableData
- Indefinitely add new version to a piece of data (this is what emulates mutability of this piece of data, when we use a GetValue() API that returns the value as of latest version.).
- O (1) on the above (both an append, as well as a read of latest value).
- Fairly fast lookup of previous versions. (I think O log(n) will be required here…)
- Writing multiple values in a single commit to a structure (for an
AD, that would be like adding a range of values in one request, where each value is appended as a new version).
AD API
-
ad.Append(value)// always appends, value directly stored in AD -
ad.TryAppend(value, expectedVersion)// optimistic concurrency -
ad.GetValue()=> (value, version) i.e. current version -
ad.GetValueAt(version)=> value -
ad.GetAll()=> array of values, where index would represent version -
ad.ReadForwardFrom(version)=> array of values from [version] to current version -
ad.ReadBackwardsFrom(version)=> array of values from [version] to version 0 -
ad.GetRange(version_a, version_b)=> order of a and b determines order of returned array // [a b], a != b, a,b > 0,
DataStore Architecture

Explanation of the components
ValueAD and StreamAD are the two different uses of an AD. For ValueAD we only care about the latest value, which we get by calling ad.GetValue(). The history is there, but it is not something we are primarily interested in, so for our purposes it is opaque (hence the 2D symbol). For StreamAD, the whole history of versions is interpreted as entries in a collection, and we have equal interest in all of them (hence the 3D symbol).
Each unit is a combination of two ADs, one acting as ValueAD and one as StreamAD, or in the leaf node level of the trees; AD and ImD. That way the unit has a fix address, but “mutable” content. The StreamAD / ImD holds the properties of the unit. Every time we need to mutate the properties of the unit, we produce a new StreamAD / ImD with the desired properties, and append a pointer for it, to the ValueAD. This way, the entire history of the unit is kept intact, while emulating mutability, since the ValueAD reference is always kept.
Detailed design
Application start
You load the address of your datastore root AD (acting as ValueAD, i.e. we care only about value at current version), from your app container.
This ValueAD contains a pointer to a StreamAD (i.e. an AD where we care about all the values/versions), in the diagram we call it DataStore Registry. Anything related to the DataStore is stored here. One such entry is the TypeStore, which is a registry of what “types” your datastore contains. So you have an “Entity_A” type, and a “Entity_B” type in this application.
In the TypeStore StreamAD, each entry is a pointer to a ValueAD. So the entry representing “Entity_A” type, points to the ValueAD for the Entity_A type. The current value of it, points to a StreamAD which has the following:
- The primary index
ValueADaddress, thisValueADlatest version points to the currentStreamADindex structure. - … n Secondary indices
ValueADaddresses, theseValueADslatest versions point to their respective currentStreamADindex structure.
This is loaded once at start.
Indices
Whenever a new index is created, the address to the new ValueAD is added to the Entity_A StreamAD. In case a type is removed, a new StreamAD is produced without the type, and the ValueAD for the type is appended with the pointer to this new StreamAD.
Writing data
The indices themselves are never appended to, as we want them to be sorted. To solve this we use LSM trees, Log Structured Merge Trees.
An in memory structure is kept, that is inserted to (and queried), and as a certain number of entries has been reached or time passed, it is flushed to network. This is either a simple addition of a new StreamAD (or tree thereof), or in case any smaller or same size tree structure already exist, it is merge sorted it in memory, until no more same size or smaller exist.
The sorted result is then sent to new instances of StreamADs (so, writing a set to each of them would be “the writing multiple values in a single commit”-feat), and new values are appended to the ValueADs that points to these new StreamAD trees (the new structure, containing the sorted entries of the existing trees, and the in memory tree).
This procedure is called compacting.
This will give log(n) number of trees which are holding our data for our specific index, each new half the size of the previous most recent.

As to support reliability, a transaction log in form of a StreamAD is inserted with any change, before it is applied to the in memory structure. In case there is a process failure before flushing, the transaction log can be replayed to rebuild the in memory structure.
Write performance is O log(n).
Accessing data
The indices are tree structures made up of ValueADs pointing to StreamADs, each entry in the StreamADs pointing to a new sub-tree of ValueADs and StreamADs.
(Basically, a ValueAD+StreamAD is like an MD entry pointing to another MD, looking at it with current design).
The leaf level of these trees, via a ValueAD, points to an ImD with the actual data.
The secondary indices point to the very same ValueAD instance as the primary index, so that we only need to update one single place in the entire structure, when the underlying data is modified (i.e. a new ImD produced).
(Remember that these StreamADs representing a level in an index B+Tree, is replaced in its entirety via the compacting process, as to avoid small writes.)
In case of B+Trees, the StreamAD entry also points to previous and next StreamAD at leaf level. As the entries are sorted, range queries can be made by first doing a point query, and then scanning from there on, until the end of the range has been hit.
As mentioned above, for any given query, there will be multiple indices to hit. First the in memory one, and then the most recent persisted, and then the next (which is double the size), and next, and so on. There are actually log(n) of them, each taking O log(n) to query. Using Bloom filters and using them selectively (as they also need to be kept in memory) will improve the query performance (which would otherwise go to O log(n)^2 ) and bring it back closer to O log(n).
Problems
Atomicity
When compacting, we are replacing existing trees with a new. We want this operation to be atomic.
However, the tree consists of multiple ADs, which could support atomicity for multiple values committed to each of them, but would have a lot harder to support it over all of them together.
This brings up the need for coordination of reads and writes to the trees, as to not get data races.
One way is to use locks, but that is very inefficient especially in a distributed environment.
A database called Noria - written in rust, implemented over RocksDb - has an interesting technique to avoid read-write locks. Overview starts right here in this youtube presentation: Rust at speed — building a fast concurrent database - YouTube.
Perhaps this could be utilized in some way, to avoid read-write locks on compactions.
On the other hand, perhaps it will be as simple as just appending a new value at the root level of a tree, and get an atomic switch by that.
Data buildup
LSM trees is not a new concept. It has been used in filesystems for example; Log Structured Filesystems.
The way this works without filling up the hard disks, is that old unused data is garbage collected.
Now, if this principle is to be used on SAFENetwork level, and SAFENetwork is supposed to be a globally used data storage and computing network, then it is fair to say that we will experience the same data build up at micro level (individual computers), and thus also at macro level? The one important difference would be that there will be no garbage collection of unused data in SAFENetwork.
Will the data capacity needs be different just because we amass computers of the world population? I don’t know. Sure a growing network would have good chances of swallowing the data increase. But a mature network? Why would it differ from the needs of individual computers (HDDs/SSDs)?